
Pare essere una delle news SEO più interessanti degli ultimi 10 anni.
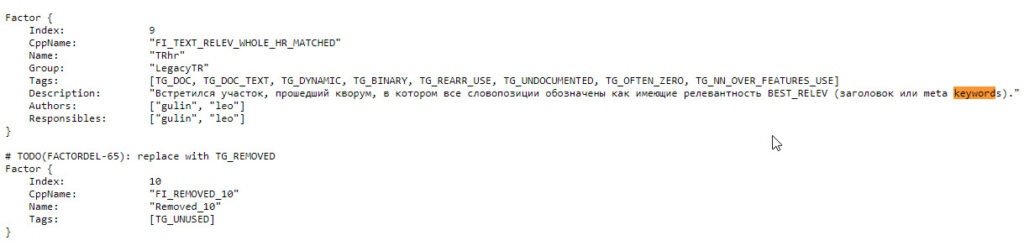
Un ex dipendente di Yandex avrebbe accidentalmente diffuso un repository di codice sorgente; parte del quale contiene più di 1.900 fattori utilizzati dal motore di ricerca per la classificazione dei risultati.
Pare infatti che questi 1.922 fattori siano in uso da Yandex nell’algoritmo di ricerca sicuramente fino a luglio 2022.
Martin MacDonald ha affermato: “La violazione di Yandex è probabilmente la cosa più interessante che sia successa in SEO negli ultimi anni”.
Ricordiamoci che Yandex non è Google: se si nota un fattore di classificazione elencato da Yandex, ciò non significa che Google dia lo stesso peso a quel segnale.
Detto questo, molti di questi fattori di classificazione potrebbero essere abbastanza simili. Pertanto, l’esame di questo documento potrebbe fornire alcune utili informazioni per comprendere meglio come funzionano i motori di ricerca e avere qualche interessante e ulteriore spunto 🙂
In tutto questo “marasma” Yandex ha negato e fornito la seguente dichiarazione:
“Yandex non è stato violato. Il nostro servizio di sicurezza ha trovato frammenti di codice da un repository interno nel dominio pubblico, ma il contenuto differisce dalla versione attuale del repository utilizzato nei servizi Yandex.
Chi volesse vedere il file può andare al seguente link: https://webmarketingschool.com/wp-content/uploads/2023/01/factors_gen.txt
Esiste anche un app per navigarli: https://yandex-explorer.herokuapp.com/search?q=Click&o=all&s=08
Alcune considerazioni iniziali
Ovviamente ci vorrà del tempo per analizzare e capire il file, ma proviamo a dare una primissima interpretazione.
Yandex è molto popolare in Russia, Bielorussia e alcune tra le ‘repubbliche’ dell’Asia centrale. Secondo il thread di Twitter di Alex Burak sulla fuga di notizie (che include alcuni fattori di ranking), i risultati di Yandex sono del 70% simili a quelli di Google
Uno dei fattori che mi ha colpito è ad esempio; “Average domain position across all queries” è un interessante fattore di ranking di Yandex, poiché regolarmente osservo miglioramenti del traffico organico in Google quando elimino pagine di scarsa qualità .Quindi, se Google utilizza un fattore di ranking simile, a parte i problemi di budget di crawl su siti di grandi dimensioni e la qualità generale del sito, potrebbe essere un’altra ragione per cui il traffico migliora in tali contesti.
Da questa discussione su Twitter si evincono altri spunti interessanti:
You probably heard about Yandex, it’s the 4th biggest search engine by market share worldwide. Yesterday proprietary source code of Yandex was leaked.
— Alex Buraks (@alex_buraks) January 27, 2023
The most interesting part for SEO community is: the list of all 1922 ranking factors used in the search algorithm
[🧵THREAD] pic.twitter.com/6x82AAmbON
- Il traffico e la percentuale di traffico sono un fattore positivo
- Da Wiki si ottiene un boost
- Molti ” slashes” nelle URL sono negativi
- L’età dei link è un fattore di ranking
- I numeri nelle URL sono negativi
- Molti fattori di ranking sono legati al comportamento dell’utente – CTR, ultimo clic, tempo sul sito, tasso di rimbalzo.
- L’età del documento/pagina e l’ultimo aggiornamento sono entrambi fattori di ranking
- La posizione media del dominio in tutte le query è un fattore di ranking
- La affidabilità del host è un fattore di ranking
- Acquistare PPC influisce sulle classifiche.
Analizziamo un attimo il tutto
Il posizionamento nei motori di ricerca è un argomento complesso e in continua evoluzione. Yandex, uno dei principali motori di ricerca in Russia, utilizza una serie di fattori per determinare il ranking di un sito web. Dall’analisi del documento possiamo “supporre” e ipotizzare che:
Uno di questi è il numero di clic e il relativo CTR (click-through rate), che è stato a lungo sospettato di essere manipolabile. Con i fattori di ranking trapelati recentemente, abbiamo ulteriori conferme di questa affermazione.
Le prestazioni complessive del sito, come il numero di volte in cui un URL e un host vengono richiesti, sono anche un fattore importante. La costruzione dell’URL è un altro elemento cruciale, con più di 130 fattori di ranking che si concentrano sull’URL. Ad esempio, l’uso di troppi slash finali o di numeri nell’URL può essere visto come negativo, mentre l’inclusione di un paese o una città corrispondente all’utente o una relazione semantica con la query può essere visto come positivo.
Inoltre, Yandex utilizza un modello chiamato DSSM (Deep Structured Semantic Model) per determinare se una pagina web contiene un solo prodotto o più prodotti. .
Yandex utilizza anche i punteggi di qualità delle pagine, che possono essere predetti utilizzando DSSM e calcolati utilizzando la qualità della pagina aggregata dall’host. Questo mostra che l’host svolge un ruolo importante nella qualità percepita della pagina e che gli host a basso costo possono essere associati a siti web di spam a basso costo.
In generale, un consiglio semplicistico per migliorare il posizionamento su Yandex è quello di mantenere gli URL semplici e incentrati sulla query di ricerca, utilizzare una costruzione di URL ben pensata e creare contenuti di alta qualità su un host affidabile.
E’ importante notare inoltre che, come per ogni motore di ricerca, anche Yandex è in continuo aggiornamento e miglioramento, quindi è importante tenere sempre sotto controllo gli ultimi sviluppi e aggiornamenti per ottimizzare al meglio il proprio sito web.
Inoltre, è importante notare che manipolare i clic non è una pratica consigliata e può portare a sanzioni da parte di Yandex. La vera chiave per il successo nell’ottimizzazione per Yandex è fornire contenuti di qualità e un’esperienza utente eccellente per gli utenti.
Quindi possiamo applicarli a Google?
Tenendo inoltre presente che vi è stato il coinvolgimento di un ex-Googler presso Yandex e supponendo che i risultati di ricerca di Yandex siano simili al 70% a quelli di Google, noi SEO dovremmo trarre delle conclusioni?
Assolutamente no!
Ad esempio, i codici di stato 4xx e altri errori del server sono elencati come fattori di ranking negativi di Yandex, ma ciò non significa che si debba correggere ogni singola URL 404 che Googlebot esplora per ottenere un miglioramento di ranking.
Voglio ricordare che molti di questi fattori Yandex non si applicheranno a Google.
Come per la maggior parte delle cose, utilizziamo si i dati disponibili per informarsi, ma senza mai dimenticare la logica.
Al Marketing Business Summit avremo una super Masterclass SEO avanzata e tantissimi interventi per scoprire come sfruttare al massimo la SEO nel 2023…
Fonti:Alex Harford ,Search Engile Land, Twitter
